
Design map: CQRS
CQRS is CQS applied at large scale.
An unfortunate name
CQRS has a confusing name as it stands for Command Query Responsibility Segregation, which are the same terms as CQS but with the added “Responsibility”, which really adds nothing to the meaning.
It’s a rather bad name because it doesn’t reflect the different between CQS and CQRS: namely that CQRS is CQS applied on large parts of the system.
But CQRS is the adopted name now so what matters is to know what it means.
Separating read and write concepts
The idea of CQS is to have separate functions for modifying data (a.k.a commands) and just providing data (a.k.a. queries).
CQRS goes further by applying this concept not just at the level of the function, but at the level of the system: all the code related to modifying data is on one side, and all the code that is related to querying data on the other side.
This includes the representation of the data itself, that could be different is each case.
This is one of the selling point of the CQRS (along with performance gains by having DB accesses specialized in reads and writes): in some domains, the concepts related to querying data are so different than those for modifying it, that trying to unify those concepts would lead to complicated code with conflated responsibilities.
Let’s take an example: a bank application needs to handle the operations made by the bank’s customers. Customers make transactions by withdrawing money or purchasing things with their credit card, and at the end of the month the bank sends them a statement presenting their operations.
One way to represent this system with CQRS is this:
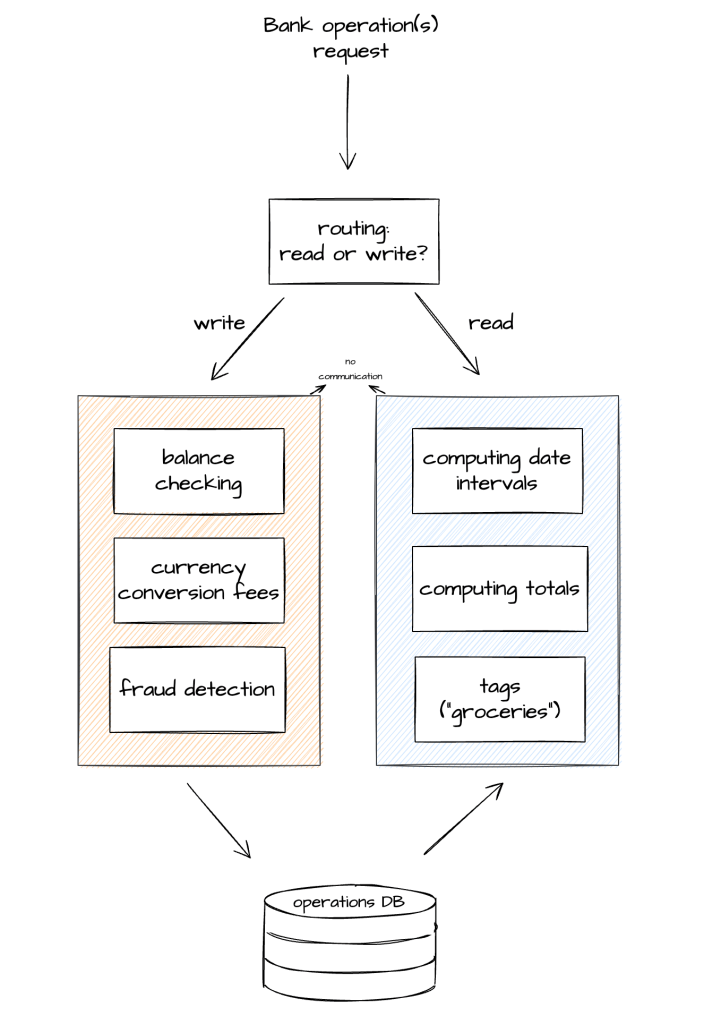
The concepts related to creating bank operations (in orange above) are very different from the concepts related to reading bank operations (in blue above).
CQRS would consist in having separate parts of the system to handle each, so as not to mix those unrelated concepts in the code, and prevent coupling from appearing between them.
An even larger application of CQRS is to have separate storage. One storage would represent the data in a form that represents the concepts of read, and the other in a form that represents the concepts of write. This requires some form of mechanism to synchronise the read database with the write database:

Which becomes a very elaborate system.
Is the separation worth it?
While it is a good thing to reduce coupling and to isolate the modifications of data, putting in place a full-fledged CQRS comes with its share of complexity.
First, having two or more databases creates a need for synchronisation along with all the issues that come with distributed systems.
But even with the first version of CQRS with one database and only separating the read and write concepts in the code, it is also worth considering if other separations would be more natural and create less coupling over the long term.
Indeed, is read and write the real differentiation between the use cases, or are they hiding different themes in the applications, that have their own read and writes? In our application that could be “authorization” and “reporting” for example, with they own needs for reads and writes.
One sure thing is that it’s good to know what CQRS is about, in order to recognize it in existing code, having it in your toolbox, or discussing it with other developers for example.
It’s always beneficial to consider several different designs before choosing one for an application. CQRS might be a good fit for some cases, but often it is perceived as not carrying its own weight in complexity (see Martin Fowler’s article on this).
Key points:
- CQRS has a poor name but means CQS at large scale
- CQRS is about separating read concepts from write concepts when they’re different
- It can go as far as having separate databases
- CQRS comes with its lot of complexity, carefully review your design options before picking one