
The Shapes of Code
Every piece of code we write is unique, or pretty much. However, there are things that are common in a lot of code, even across various codebases, and even across various languages: the physical shape that code has.
Beyond the mere visual aspect of code, the shape of a piece of code can carry information by itself. Being able to decipher this information allows to glean indications about the code at a glance, even before starting to read it. This information is valuable in itself, and afterwards during the reading of the code itself.
It is by listening to an episode of Developer Tea that I came across the idea of looking at the shape of code, the physical pattern formed by lines of code if you squint at them or look at them from afar.
This got me thinking about the various physical patterns we encounter in code, and what benefits we can draw by recognizing those patterns. The benefits are at least of two kinds: understanding the code more quickly by taking a step back, and recognizing opportunities to improve the code by refactoring it.
Here are some typical code patterns, along with guidelines on what to do with them. I’m sure there are lots of others, and if you can think of some of them, please reach out to me, I’d love to hear about them!
The saw-like function
This was the one that made me think about the shape of code in the first place when listening to the podcast. It is a piece of code that looks like this:

It goes back and forth in terms of indentation and length of line, which makes it look like the edge of a saw:
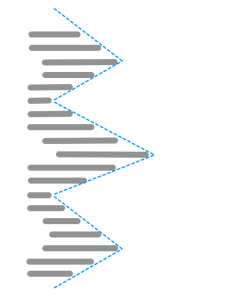
This is generally complex code, but each spike tends to have one concern.
Benefit for understanding: each spike can be analyzed on its own for a start (even though they may depend on each other)
Benefit for refactoring: each spike is a potential candidate for taking code out to a separate function, and replacing it with a call to that function. However, if the code is mixed up between spikes, you may need intermediary steps to untangle them before.
The paragraphs
Like in the layout of a book, some code consists of blocks that are spaced out with blank lines in between, thus creating “paragraphs”:

This code has been organized to show that it consists of several steps. The first block of code is step #1, the second block is step #2, and so on.
Benefit for understanding: You know that the algorithm operates in steps, and you know where the steps are located in code.
Benefit for refactoring: Since steps are by definition supposed to be somewhat delimited from each other, each step is a good candidate for offloading its code to a function. The resulting code would be a sequence of function calls. This would raise the level of abstraction and make code more expressive.
The paragraphs with headers
This is a variation from the previous pattern: each paragraph is preceded with a comment that describes what the step consists of:

Benefit for understanding: Same as above. The developer who wrote this made the task easier for you by adding information about each step.
Benefit for refactoring: Same as above. You can use some terms in the comments as inspiration for function names. After refactoring, the comments become redundantand can be removed.
The suspicious comments
Some functions look like a nice sequence of function calls, accompanied by comments to make code even more expressive:

But not all comments are beneficial, and the above pattern is often not so good code: if it was, we wouldn’t need a comment to explain each line of code.
This is often a issue related to naming: the name of the functions and the ones of their parameters are not clear enough to be understandable on their own.
Benefit for refactoring: use the terms in the comments to rename the function and their parameters, and remove the comments.
The intensive use of an object
Some objects are used intensively at some point of a function, and much less afterwards. If we highlight the occurrences of that object in the function (with a simple press of ‘*’ in Vim or Ctrl+F in Visual Studio), we see a local portion illuminate with its uses:

Benefits for understanding: the role of that chunk of code is to set up that object. It can be to set it up for the rest of the function for example.
Benefits for refactoring: the function has several responsibilities, and one of them is to work with that object. Offload this responsibility to a sub-function, to reduce the number of responsibilities (ideally to one) of the main function.
The unbalanced if statement
Some if statements have a much larger if branch than their else branch:

It can also be the other way around, with a disproportionate else branch:

This often means that the two branches of the if statement are not at the same level of abstraction: the larger branch gets into lower-level concerns than the shorter one.
It can also mean that the shorter branch is an error case, and its body is about getting out of the function as quickly as possible.
Benefit for refactoring: If the smaller branch is an error case, consider using a guard instead of the whole if/else construct to simplify the code. If the larger branch is concerned with low-level code, pack it into a sub-function and replace the code with a call to that sub-function.
The shape of code is a heuristic
All the above guidelines are rather heuristics than hard rules. They’re often useful to get an idea of the structure of a function and think of how to refactor it.
This list is by no means comprehensive. There are plenty of other physical patterns in code out there, and it would be useful to keep collecting them. What other patterns do you know? Reach out to me to share the patterns that you come across frequently.
You will also like
- It all comes down to respecting levels of abstraction
- On using guards in C++
- How to design early returns in C++ (based on procedural programming)
- To comment or not to comment? // that is the question
Share this post!
